Full Length Research Paper

ABSTRACT
INTRODUCTION
In order to meet the future food and nutrition demands of an increasing population in southern Africa, and to make optimal use of marginal land, there is need to start research on little known edible plant species that offer great potential. Tylosema esculentum (Marama bean) is one of those research neglected plants. Marama bean is found in Namibia and Botswana in large populations and small populations in Gauteng, South Africa (Chingwaru et al., 2011). Marama bean is a species in the legume family that produces pods and bean-like seeds perennially. It is native to dry areas of Kalahari agro-ecological zones with little seasonal rainfall. It is particularly important in subsistence agriculture (Müseler and Schönfeldt, 2006). These neglected crops are usually accepted by the local population and better adapted to existing environmental conditions. The potential to provide a more stable food supply for a drought stricken Africa has been reported (Müseler and Schönfeldt, 2006). The plant is a nutritional and valuable food source and can be successfully used in programs specifically aimed at improving household and food security and in programs aimed to improve protein deficiency in southern Africa.
T. esculentum is a non-nodulating, undomesticated tuber-producing legume, abundant in protein, oil and starch (Takundwa et al., 2010). The bean and tuberous root extracts of the plant have also been used as medicine (Chingwaru et al., 2011). Despite abundance of protein, oil and starch, the plant has low yields, producing one or two seeds per pod. With the advent of bioinformatics, researchers have sequenced some legume genomes. The prominent ones are soybean (Glycine max), barrel medic (Medicago truncatula) and birdsfoot trefoil (Lotus japonicus), common bean (Phaseolus vulgaris), mungbean (Vigna radiata), red bean (Vigna acutifolius), narrow-leafed lupin (Lupinus angustifolius), wild peanut (Arachis duranensis and Arachis ipaensis), pigeon pea (Cajanus cajan) and chickpea (Cicer arietinum). The impact of these assembled, annotated genomes has been enormous. These genome sequences are useful for genome comparisons and to transfer information from these biological models to other crop species and vice versa (Cannon et al., 2009). Besides the genome sequencing of some legumes, researchers have also analyzed and exploited ESTs of some plant species in order to understand them better. These powerful tools are used to gain further insight in the molecular manifestations of growth, development, ripening and survival of the organism studied. ESTs have proven to be an economically feasible alternative for gene discovery in species lacking a draft genome sequence (Matukumalli et al., 2004), such as the T. esculentum.
An expressed sequence tag (EST) is a short sub-sequence of cDNA derived from cellular mRNA and thus represents part of a protein-coding gene (expressed genes). ESTs are short (200-800 nucleotide bases in length); unedited, randomly selected single-pass sequence reads derived from cDNA libraries (Nagaraj et al., 2006). EST libraries have been developed for plant species such as tomato, apple, rice, grape and citrus (Gonzalez-Ibeas et al., 2007). However, amongst the comprehensive ones are Arabidopsis thaliana and Oryzae sativa which are the common models for analysis (Gonzalez-Ibeas et al., 2007). Bioinformatics tools can be used to identify and dissect biological processes that are of great technological importance such as flavor development and fruit ripening through the analysis of ESTs (Gonzalez-Ibeas et al., 2007). Gene mining can be used to select candidate genes that are associated with traits of interest (Frank et al., 2004; Higgs and Attwood, 2005). The EST collections can also be used to develop microarrays to identify genes expressed during plant developmental stages and/or responding to environ-mental stimuli as well as to gain deeper understanding of the common regulatory mechanisms amongst diverse fruit species and ripening physiological patterns (Gonzalez-Ibeas et al., 2007; Fei et al., 2004). Some previous studies have used this analysis to identify genes involved in fruit ripening and pathogen defense (Gonzalez-Ibeas et al., 2007).
T. esculentum has no genome draft. Nonetheless, due to its economic and agricultural potential, it is imperative to explore what genes and microsatellites can be efficiently and rapidly mined and identified. Delayed or inefficient analysis due to tool constraints or lack thereof may impede development of potential products such as molecular markers, beneficial genes and useful biochemical pathways. The objectives of this study were to identify genes and microsatellites represented in the ESTs library developed for marama bean.
MATERIALS AND METHODS
ESTs generation and bioinformatic analyses
RNA was extracted from the embryogenic axis of germinating marama bean seeds using a Qiagen RNA extraction kit (Qiagen, Germany) and this RNA was used to construct the ESTs library using an oligo-dT primer based cDNA synthesis kit (Roche, Germany). Pyro-sequencing with 454 Sequencing technology was used to directly sequence the resultant derived cDNAs without using vectors. For the analysis of datasets, a Window 7 professional, 32-bit operating system and Intel (R) Celeron (R) CPU at 1.80 GHz computer was used together with an internet connection. T. esculentum ESTs datasets were analyzed using on-line detached programs. There were two EST datasets that were analyzed: the marama bean single reads and the marama contigs datasets. On average, the ESTs were between 50 and 276 bp for the single reads and 100 and 718 bp for the contigs.
The single reads dataset contained 13,582 sequences which were multiple aligned using ClustalW (www.clustalw.com). This was the preliminary processing to ensure minimum redundancy of sequences. Sequences (20) were aligned at a time. After multiple sequence alignment, 10,660 sequences remained. The sequences clustered as similar scored 90% or higher. The longest sequence of each batch was selected for downstream processing.
A BLASTn search was run against the non-redundant nucleotide database of NCBI’s Genebank (www.ncbi.nlm.nih.gov/BLAST/). Default search parameters were used. After the BLASTn, a tBLASTx search was done on the sequences that produced significant alignment hits. Non-plant genes and similarity alignments with E-value >0.01 were disregarded.
The marama contigs were also processed similarly, multiple aligned using ClustalW and then searched against the Arabidopsis database, using the default TAIR BLASTn search parameters (www.arabidopsis.org/BLAST/). The sequences before and after multiple alignment were 924 contigs. The alignments with E-value < 0.5 were considered significant. Contig sequences (50) were analyzed. The single reads that gave significant similarities were scanned for SSRs using an SSR search tool (SSRIT) (www.gramene.org/db/markers/ssrtool).
RESULTS
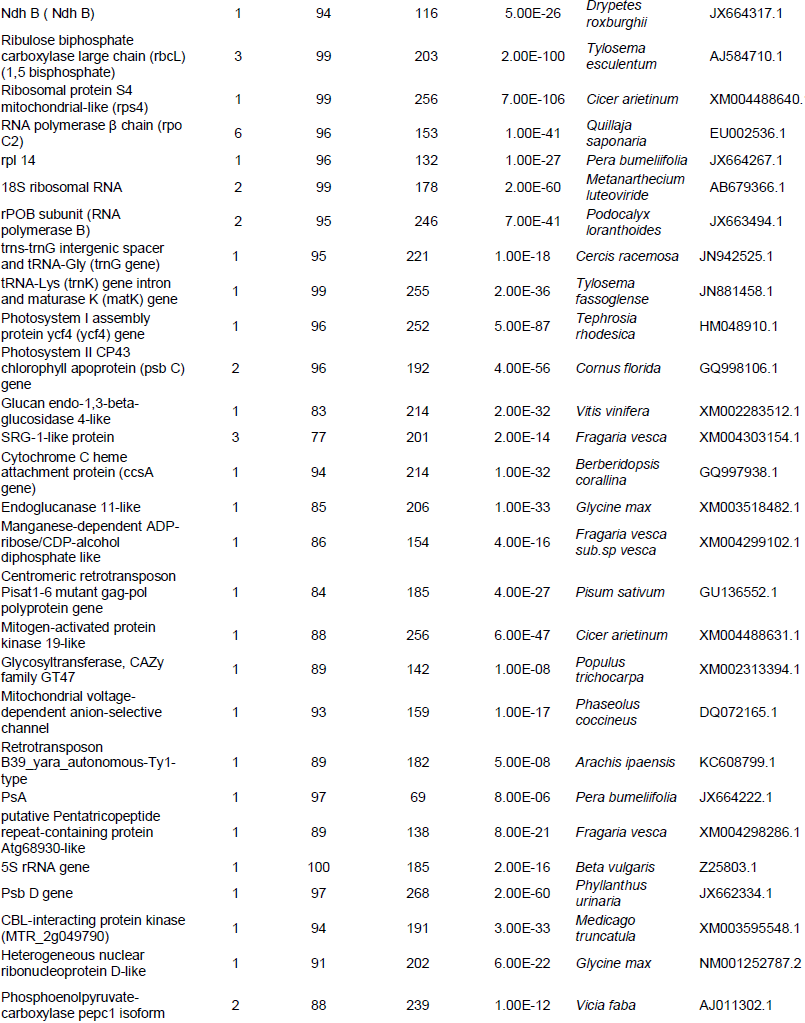
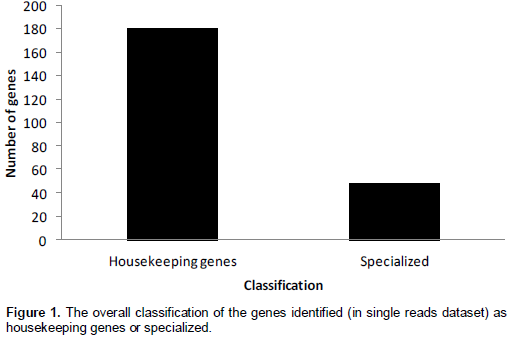
After the analysis of 3247 out of 10660 sequences in the single reads dataset, 227 genes and proteins were identified to be of plant origin. The genes identified were found to be involved in essential cellular and metabolic processes in other various plants (Table 1). These were classified as housing keeping genes (79% of the total predicted proteins) and those that did not exhibit high frequencies are classified as specialized (29% of the total predicted proteins) (Figure 1). It was also observed that some of the important putative marama bean genes that were identified and are worth investigating were similar to rps 2; disease resistance; retrotransposons B39_yara_autonomous TY1-type, glycosyltransferase CAZy family GT47; tRNA-Lys (trnK) gene intron and maturase K (matK) gene; centromeric retrotransposon Pisat1-6 mutant gag-pol polyprotein gene; inverted repeat B; RING/FYVE/PHD zinc finger superfamily and transposable element gene. Tables 2 and 3 show the genes that were identified with BLASTx from the single reads data base and TAIR BLASTn from the large contigs, respectively. Table 4 shows the microsatellite repeats that could be mined in the GRAMENE database using SSRIT microsatellite search tool.
.png)
.png)
.png)
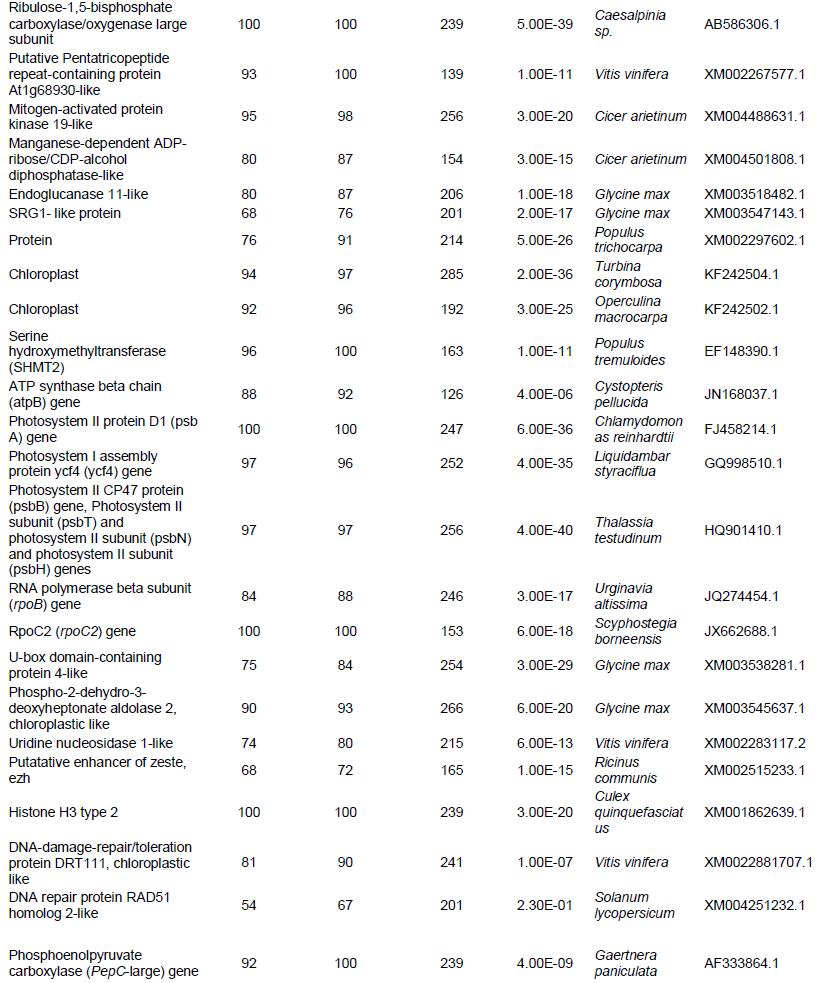
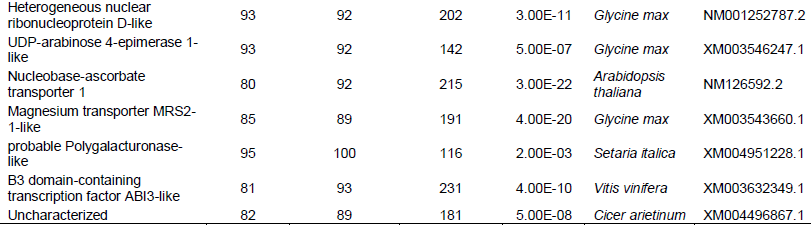
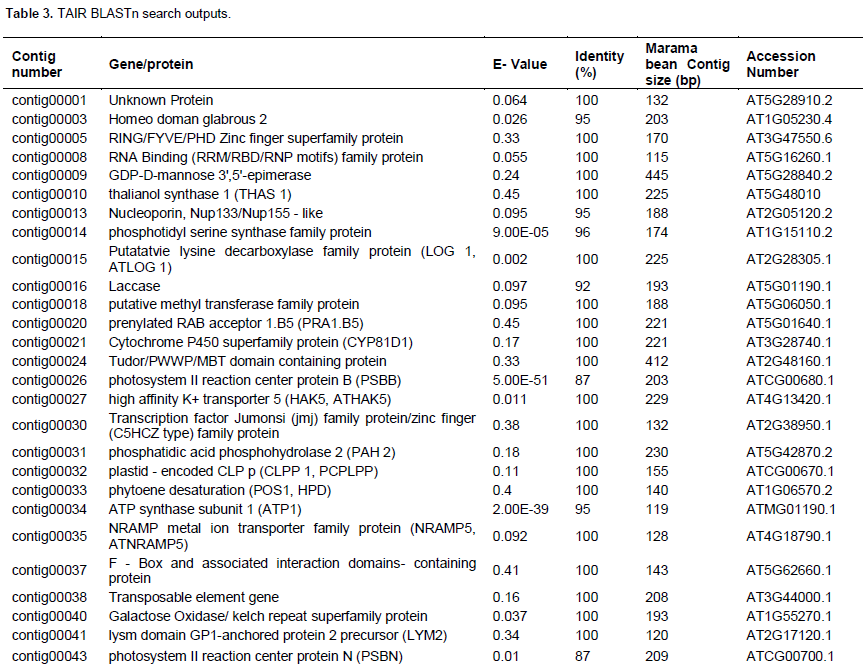


For the large contigs dataset, 50 out of 924 sequences were searched against the Arabidopsis database and 34 genes with high similarities were found. In this study, microsatellite sequences were identified and genes associated with these SSR markers were identified to be closest to CBL interacting protein kinase (MTR_2g049790) with (CT) repeats; mitochondrion like with (GA) repeats; NA Damage-repair/toleration protein DRT111 and chloroplastic gene with (TC) repeats and lastly galactosyl transferase 11-like gene with a (TTG) repeats.
DISCUSSION
The objectives of this study were to identify genes and microsatellites from the EST single reads and contigs libraries as the first approach of identifying functional genes in marama bean at the embryonic seed stage. The plant lacks a genome draft and therefore has an unknown genome size. Due to the potential of the plant and the endeavors to domesticate it, functional genomic information is necessary to identify and map biochemical pathways and also to design primers for microsatellites. Genes (180) and proteins were identified in the single reads dataset that are involved in photosynthetic and energy processes. Genes (47) from the single reads dataset and the 34 genes identified in the contigs dataset are involved in processes such as transcription, transport, cellular communication, disease resistance and DNA repair.
Within all the genes identified in both the single reads and contig datasets, 7 genes identified have important uses in plant disease resistance as well as in plant biotechnology. For instance, rps2 gene is involved in disease resistance, while retrotransposons and transposons can be used in mutagenesis and plant evolutionary studies (Kumar and Bennetzen, 1999). In this study, the longest marker identified contains three base repeats and the rest contain two bases (dinucleotide repeats). Some genes associated with markers are involved in cellular transport and DNA repair such as DNA repair protein RAD51 homolog 2-like. It still remains to be evaluated how useful will these markers be in the selection and breeding of marama bean with desired superior traits. Similar studies have been done on plant to develop and use microsatellite markers for genetic variation analysis in the Namibian germplasm within and between populations using ESTs. The markers are now available for use in efforts of domestication and conservation. Takundwa et al. (2010) stated that it is desirable to isolate and characterize more DNA markers in the plant for more productive genetic studies such as genetic mapping, marker associated selection and gene discovery. In a study by Bombarely et al. (2010), ESTs were generated and analyzed in the evaluation of Fragaria xananassa at a genetic and molecular level. The analysis of the transcription analysis generated knowledge and molecular tools that would be essential in ongoing breeding programs and had also allowed the development of molecular markers that have been applied to germplasm characterization. ESTs have also been used in studies of plants such as tomato to understand tissue specific genes and biological responses in fruit ripening (Fei et al., 2004), and the fruit traits were studied using ESTs for melon (Cucumis melo). The genes of interest were the genes in the essential traits such as fruit development, fruit maturation and disease resistance, and to speed up the process of breeding new and better adapted melon varieties, such genes are yet to be studied in marama bean.
CONCLUSION
This study has demonstrated the first significant progress in the identification of genes using EST database gene mining for advancing molecular breeding and biotechnological crop improvement for this species, T. esculentum. If a sequence is known, microsatellites and markers can be identified, and then marama bean-specific primers can be developed. Genes that have been identified in marama bean are involved in energy generation, disease resistance, transcription, maturation and DNA repair.
There are a lot more genes to be discovered and studied beyond what this study has discovered for marama bean. In marama bean, traits of interest are, but not limited to increasing number of seeds per pod produced by the plant, selecting for early flowering and early germination (Takundwa et al., 2010). In breeding programs, traits of interest can be linked to markers, which can be used for marker associated selection which
is time-saving than traditional breeding. The legumes are remarkably well positioned in the genomic era.
Future perspectives
In the future, it will be important to identify and characterize more genes and traits, and to extend new genomic tools to orphan species like marama bean. Some of the most critical work does not only rely on new high-throughput sequencing or genomic technologies. This includes characterizing and managing germplasm collections and breeding lines in many species; developing mapping populations for various traits of interest in less-studied species. Working with indigenous farmers ensures that the by-product of centuries of conservation and indigenous knowledge are not lost. Investigating protocols for hybrid seed production in various legumes; and working to maintain and develop under-studied legumes for use in diverse, challenging growing environments around the globe is a responsibility to help diversity crops for a changing world climate (Cannon et al., 2009).
The rapid increment in the information and data generation in plant science, demands for tools and methods in data management, visualization integration, analysis, modeling and prediction has also increased (Useche et al., 2001, Rhee et al., 2006; Frank et al., 2004). In this regard, bioinformatic analysis is a utility. This specific knowledge can then be used to produce stronger, more drought resistant crops and improve the quality of livestock, making them healthier, more disease resistant and more productive (Singh et al., 2011).
CONFLICT OF INTERESTS
The authors did not declare any conflict of interest.
REFERENCES
|
Bombarely A, Merchante C, Csukasi F, Cruz-Rus E, Caballero JL, Medina-Escobara N, Blanco-Portales R, Botella MA, Munoz-Blanco J, Sanchez-Sevilla JF, Valpuesta V (2010). Generation and analysis of ESTs from strawberry (Fragaria xananassa) fruits and evaluation of their utility in genetic and molecular studies. BMC Genomics 11(503):1-17. Crossref |
||||
|
Cannon SB, May GD, Jackson SA (2009). Three sequenced legume genomes and many crop species: rich opportunities for translational genomics. Plant Physiol. 151: 970-977. Crossref |
||||
|
Chingwaru W, Majinda TR, Yeboah SO, Jackson CJ, Kapewangolo PT, Kandawa-Schulz M, Cencic A (2011). Tylosema esculentum (Marama) tuber and bean extracts are strong antiviral agents against rotavirus infection. Evid. Based Complement. Alternat Med. Article ID 284795, 11 pages, 2011. doi:10.1155/2011/284795. Crossref |
||||
|
Fei Z, Tang X, Alba RM, White JA, Ronning CM, Martin GB, Tanksley SD, Giovannoni JJ (2004). Comprehensive EST analysis of tomato and comparative genomics of fruit ripening. Plant J. 40:47-59. Crossref |
||||
|
Frank E, Hall M, Trigg L, Holmes G, Witten IH (2004). Data mining in bioinformatics using Weka. Bioinformatics 20:2479-2481. Crossref |
||||
|
Gonzalez-Ibeas D, Blanca J, Roig C, Gonzalez-To M, Pico B, Truniger V, Gomez P, Deleu W, Cano-Delgado A, Arus P, Nuez F, Garcia-Mas, J, Puigdomenech P, Aranda MA (2007). MELOGEN: an EST database for Melon functional genomics. BMC Genomics 8(306):1-17. Crossref |
||||
| Higgs PC, Attwood TK (2005). Bioinformatics and Molecular Evolution. UK & USA: Blackwell Science Ltd. | ||||
|
Kumar A, Bennetzen JL (1999). Plant Retrotransposons. Annu. Rev. Genet. 33:479-532. Crossref |
||||
|
Matukumalli LK, Grefenstette JJ, Sonstergard TS, Van Tassell CP (2004). EST-PAGE- Managing and analyzing EST data. Bioinformatics 20(2):286-288. Crossref |
||||
| Müseler DL, Schönfeldt HC (2006). The Nutrient content of the Marama Bean (Tylosema esculentum), an underutilized legume from Southern Africa. Agricola 16:7-13. | ||||
|
Nagaraj SH, Gasser RB, Ranganathan S (2006). A Hitchhiker's guide to expressed sequence tag (EST) analysis. Brief. Bioinform. 8(1):6-21. Crossref |
||||
|
Rhee SY, Dickerson J, Xu D (2006). Bioinformatics and its applications in Plant Biology. Annu. Rev. Plant Biol. 57:335-360. Crossref |
||||
|
Singh VK, Singh AK, Chand R, Kushwaha C (2011). Role of bioinformatics in agriculture and sustainable development. Int. J. Bioinform. Res. 3(2):221-226. Crossref |
||||
| Takundwa M, Chimwamurombe PM, Kunert K, Cullis CA (2010). Isolation and characterisation of microsatellite repeats in marama bean (Tylosema esculentum). Afr. J. Agric. Res. 5(7):561-566. | ||||
| Useche FJ, Gao G, Hanafey M, Rafalski A (2001). High-Throughput identification, database storage and analysis of SNPs in EST sequences. Genome Inform. 12:194-203. | ||||
Copyright © 2024 Author(s) retain the copyright of this article.
This article is published under the terms of the Creative Commons Attribution License 4.0


